一,设定角色形象
生成不同角度提示词:
根据参考图片,连续生成 10 张女孩在白色背景的照片,保持这个图片的所有特征,改变拍摄视角和人物动作,
1、从地板向上看的极低角度
2、从平视角度看
3、从脸部上方的高角度向下看身体
4、高机位正俯视角度看女生全身
5、从手旁边的低角度图像,向上看手臂上的脸
6、展示面部正面近景
7、展示全身正面全景
8、展示全身侧面全景
9、展示全身背面全景
10、随机生成不同角度下女生状态
生成不同服装提示词:
保持人物面部细节与动作不变,替换相同风格不同款式的10套服装,图像比例为16:9


二,使用MJ生成参考场景
场景提示词:
- 色彩与材质:以纯净的白色为主调,搭配柔和的粉色光线,营造出轻盈、柔美的视觉基调;空间结构大量采用高反光的光滑弧形材质(如有机玻璃或特殊合成材料),光线在表面充分反射,增强了空间的明亮感与通透感。
- 空间设计:结构充满流线型的 “未来感”,弧形的拱门、圆润的台座等元素,弱化了硬朗的线条,让空间显得更有机、更具想象力。
- 核心与细节:中央有深色圆形装置(周围带网格或科技感面板,似核心交互 / 观察部件);两侧设置了粉色发光区域,搭配造型圆润的白色台座,台座上还点缀着小型植物,在科技感中融入了一丝自然生机;顶部与地面的圆形发光体提供柔和照明,进一步强化了科幻氛围。

三,使用豆包生成图像画面与分镜内容
豆包提示词:
你是一个专业的MV大片拍摄导演,需要帮我制作拍摄一个关于唱跳的MV视频,在指定场景中拍摄一部尺寸比例为16:9的MV。
场景为:(需要填写你自己设定的场景描述)
形象特征为:(需要填写你自己设定的形象描述) 使用nano banana图像编辑模型进行不同画面的图像生成,你需要针对每个分镜创建一个图像生成的提示词,(例如:图像一,聚焦女孩全身,她手持麦克风,准备激情演唱,全景视角,宽角度构图,视觉张力大 并设置16:9的尺寸比例) 然后根据生成图像的内容,设定符合画面的动态提示词(例如:展示唱跳女歌手在舞台上激情舞蹈唱歌或舞蹈的场景)

将生成的角色与场景作为参考,使用豆包给的提示词生成视频
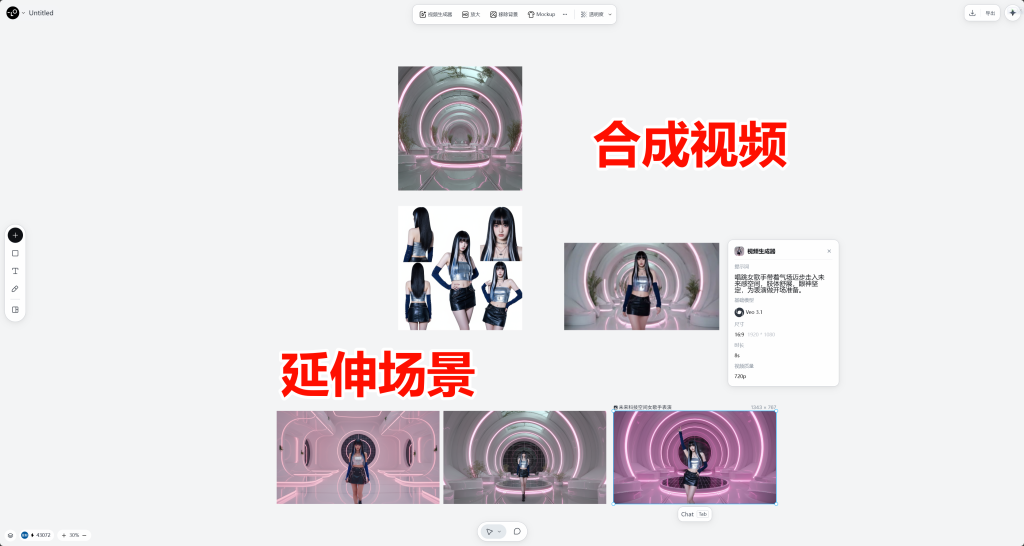


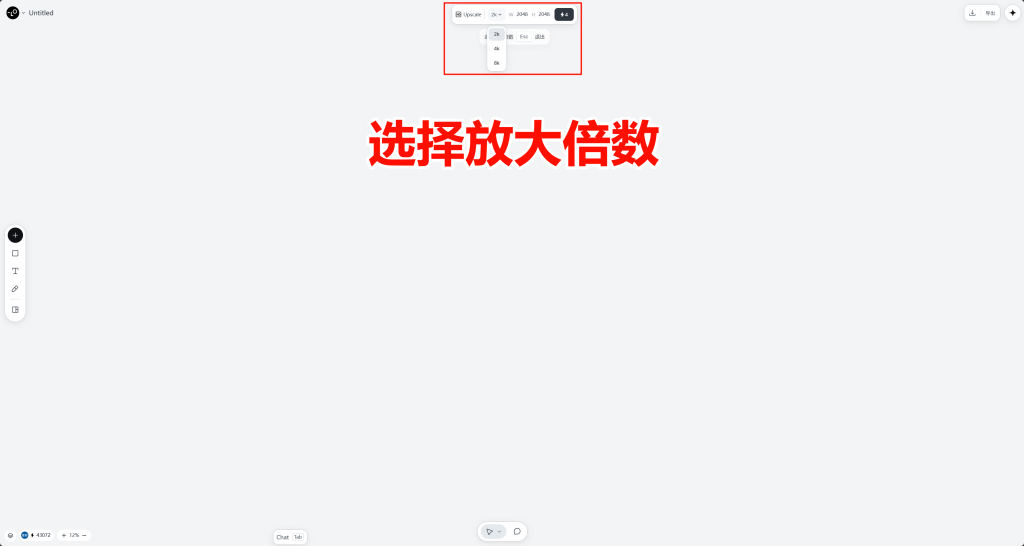
四,高清放大与面部参考
如果出现满意的动作但面部崩坏,可以先进行高清放大在使用角色形象作为参考进行面部修复

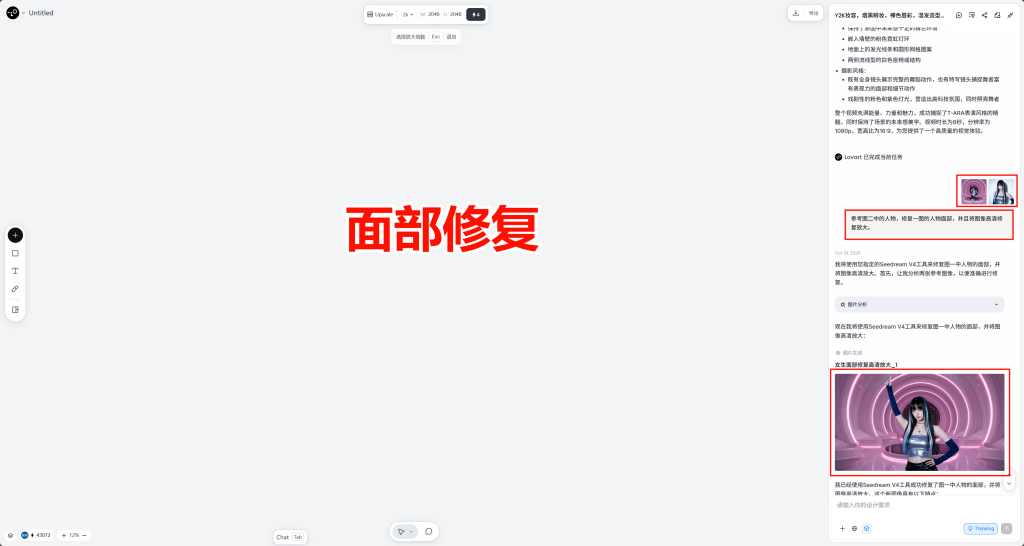
五,将生成好的视频进行配合歌曲进行口型同步。
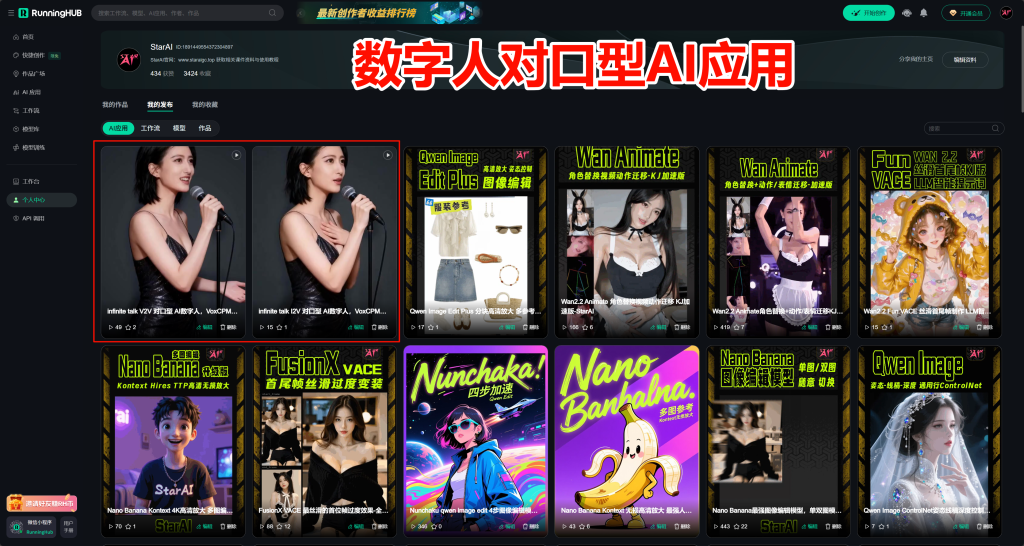
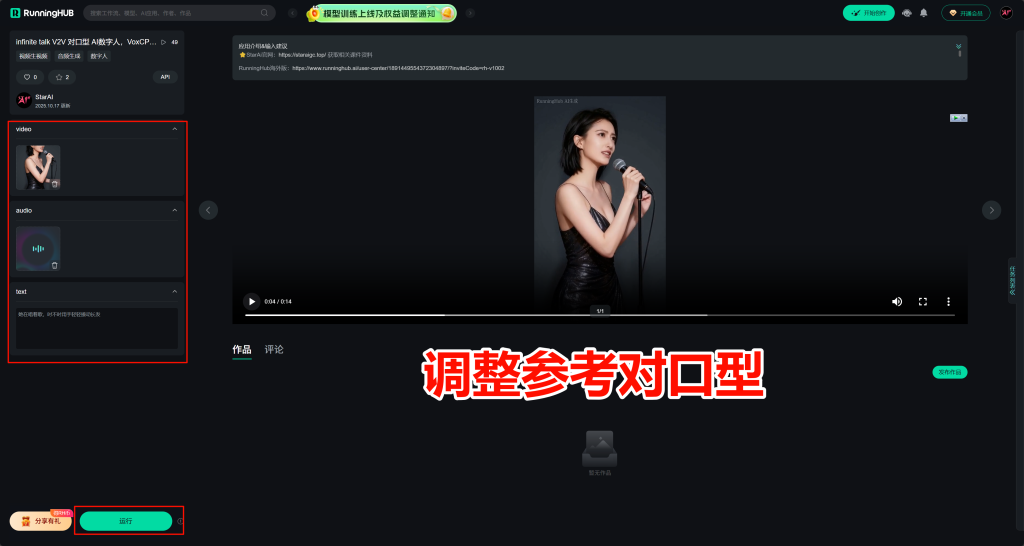
选择AI应用的驱动方式:上传视频与音频填写提示词点击运行
AI应用:https://www.runninghub.cn/ai-detail/1975671958014660610?inviteCode=rh-v1002
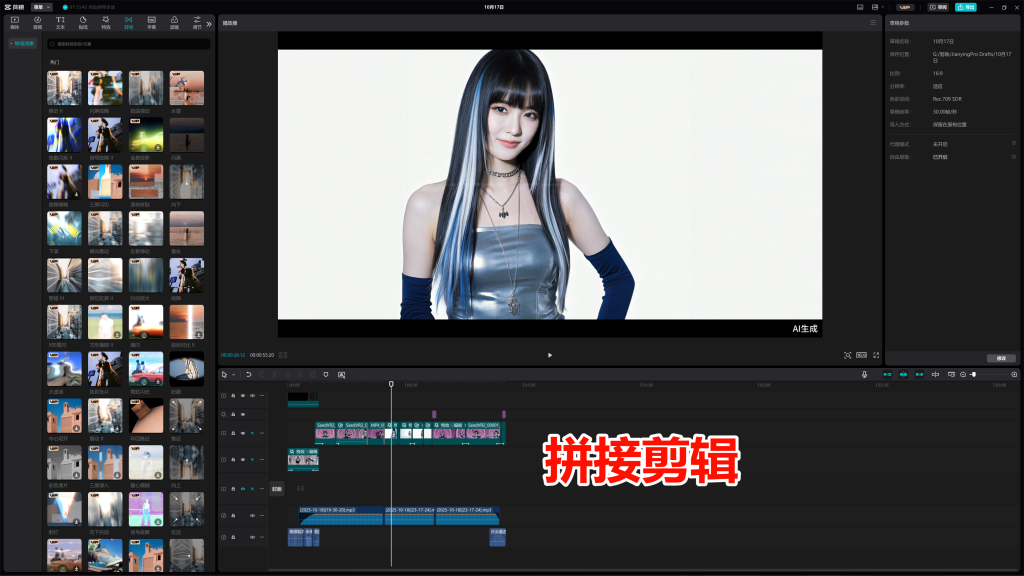
六,将生成好的视频放到剪辑软件进行拼接
Lovart官网:https://www.lovart.ai/zh/home
使用指南:https://www.notion.so/User-Guidebook-Lovart-User-Guide-1ec304d920da80bca060f58dfaa1a1ac